The problem
Markit CDS is a source for credit default swap data for quoted companies, private companies and governments. Academic researchers with access to a resource like this usually need to cross reference the securities’ fundamentals or financial data. The financial data is offered from Markit for additional cost but is already available from a university’s other subscriptions. It makes economic sense to use these two existing resources together; the hard part is matching the list companies exactly.
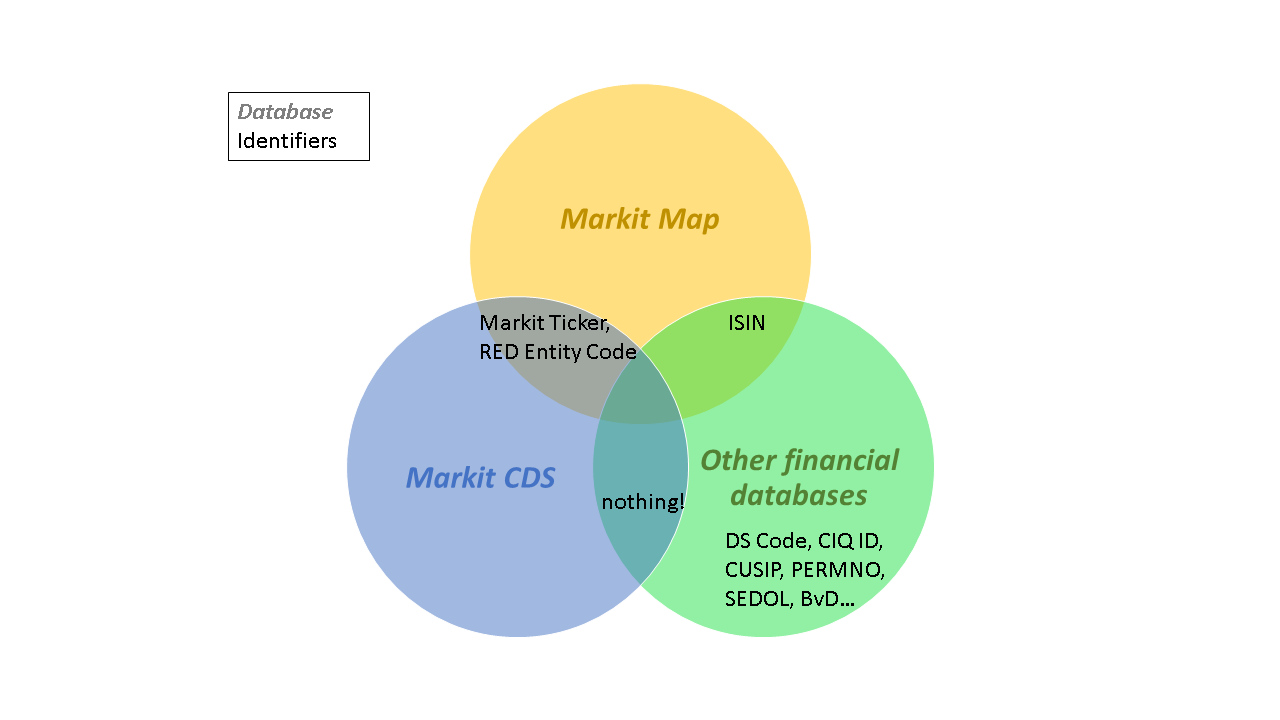
When accessing credit default swap data from Markit CDS (via the WRDS platform), if offers two types of security identifiers:
- RED Entity Code
- Markit Ticker *
When accessing company fundamentals data from Capital IQ or Datastream (for example), you can use different security identifiers:
- Thomson Reuters Datastream: DS Code *
- S&P Capital IQ: CIQ Code *
- ISIN (best for quoted companies)
- …and many others
Note: * proprietary and unique to supplier
We need a common identifier, and Security Name will not do. (Why? That’s another post!) In this case, The University of Manchester was offered a translation from Markit of Markit Ticker to ISIN (called Markit Maps). If this had been a complete table matching all the Markit Tickers to all the ISINs in history, that impossible Holy Grail would have made work much easier. Instead, we were offered the following:
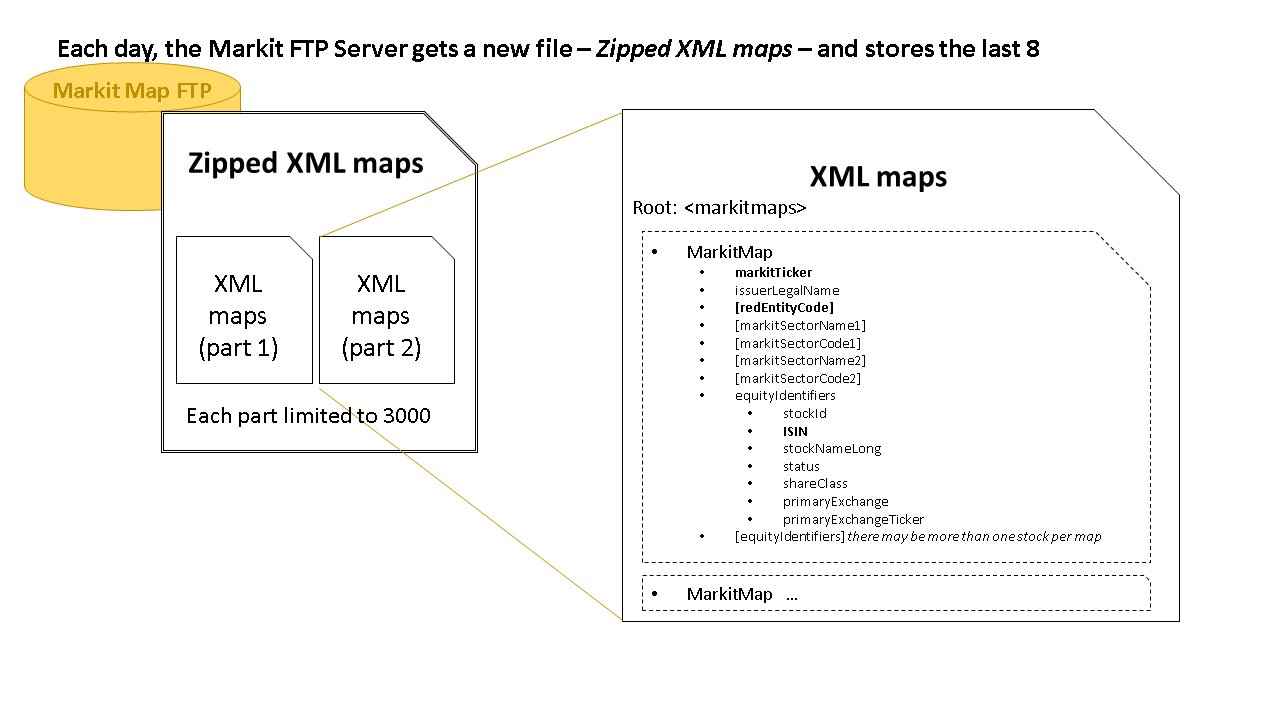
- For one trading day, a list of all the securities that had CDS activity.
- This list was in XML format and contained RED Entity Code, Markit Ticker, ISIN and Name.
- There were two XML files per day as the first one had a limit of 3,000 securities.
- These two files were in a zip file including the date in the filename.
- The most recent eight zip files were provided on an FTP server.
The necessary data for translating the last eight trading days is all there, if you can process it. For further back than eight days, we had to store the maps ourselves before they disappeared (and at first I did not know that this would happen).
The working prototype solution
The programming language I have most experience with is Java. After some experiments in BaseX I got the following structure working.
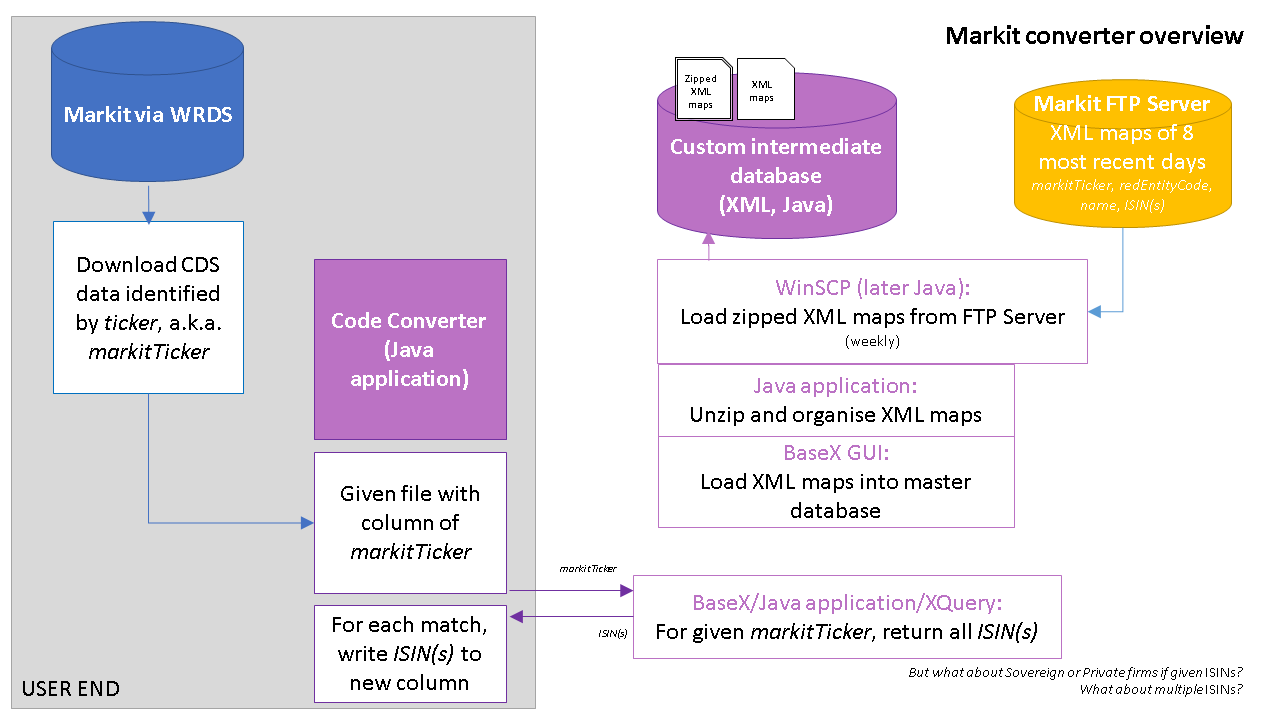
- Manually open WinSCP every week to transfer the latest Markit Maps zip files to our filestore.
- Periodically run the following preparation process in Java.
- For each date/zip file, unzip the two XML files.
- Save the two XML files with all previous ones in the existing directory.
- To create a master translation table of all the Ticker/RED to ISIN maps run this Java code.
- Begin writing out to a CSV file and recording all the ISIN codes in memory.
- For each XML file, read each Markit Map using the XQuery API for Java.
- For each Map, if the ISIN has not yet appeared, write the entry to the CSV file and store the ISIN in memory, else move on to next Map.
- Move on the next XML file then end.

A master translation table can be useful for some, but if a student has a list of Markit Tickers that they want to get a map of ISINs for, there is another function for that.
- Load all of the Markit Maps into memory as described in the process above (but without writing to CSV).
- For a text file of Markit Tickers, for each Ticker, look for that Ticker in memory.
- For each match, write out to another text file a line containing that Ticker, ISIN and Name (in CSV format).
- There may be more than one ISIN per Markit Ticker, so look through the entire database.
- Repeat until all the input Tickers have been looked for.
The next steps
The researcher can take away the list of ISIN codes to use in another database for company financial data or similar and map it into their original Markit data.
This prototype is not the most efficient approach considering compute time or space, but it was successful. I would like to automate the FTP stage to ensure that I did not miss any maps. Further, a relational database management system could be used.

One thought on “How I made Markit CDS play nice with other databases”